publications
2025
2025
- CHI
 In Suspense About Suspensions? The Relative Effectiveness of Suspension Durations on a Popular Social PlatformJeffrey Gleason, Alex Leavitt, and Bridget DalyIn Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , 2025
In Suspense About Suspensions? The Relative Effectiveness of Suspension Durations on a Popular Social PlatformJeffrey Gleason, Alex Leavitt, and Bridget DalyIn Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , 2025It is common for digital platforms to issue consequences for behaviors that violate Community Standards policies. However, there is limited evidence about the relative effectiveness of consequences, particularly lengths of temporary suspensions. This paper analyzes two massive field experiments (N1 = 511,304; N2 = 262,745) on Roblox that measure the impact of suspension duration on safety- and engagement-related outcomes. The experiments show that longer suspensions are more effective than shorter ones at reducing reoffense rate, the number of consequences, and the number of user reports. Further, they suggest that the effect of longer suspensions on reoffense rate wanes over time, but persists for at least 3 weeks. Finally, they demonstrate that longer suspensions are more effective for first-time violating users. These results have significant implications for theory around digitally-enforced punishments, understanding recidivism online, and the practical implementation of product changes and policy development around consequences.
@inproceedings{gleason2025suspensions, title = {In Suspense About Suspensions? The Relative Effectiveness of Suspension Durations on a Popular Social Platform}, author = {Gleason, Jeffrey and Leavitt, Alex and Daly, Bridget}, booktitle = {Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems}, year = {2025}, } - FAccT
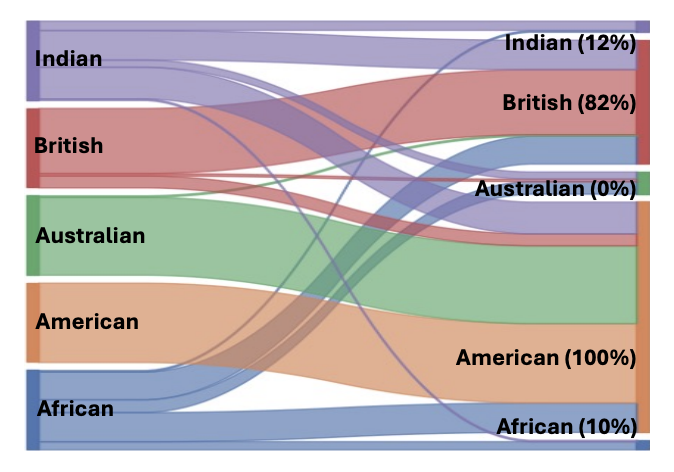 “It’s not a representation of me”: Examining Accent Bias and Digital Exclusion in Synthetic AI Voice ServicesShira Michel, Sufi Kaur, Sarah Elizabeth Gillespie, and 3 more authorsIn Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency , 2025
“It’s not a representation of me”: Examining Accent Bias and Digital Exclusion in Synthetic AI Voice ServicesShira Michel, Sufi Kaur, Sarah Elizabeth Gillespie, and 3 more authorsIn Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency , 2025Recent advances in artificial intelligence (AI) speech generation and voice cloning technologies have produced naturalistic speech and accurate voice replication, yet their influence on sociotechnical systems across diverse accents and linguistic traits is not fully understood. This study evaluates two synthetic AI voice services (Speechify and ElevenLabs) through a mixed methods approach using surveys and interviews to assess technical performance and uncover how users’ lived experiences influence their perceptions of accent variations in these speech technologies. Our findings reveal technical performance disparities across five regional, English-language accents and demonstrate how current speech generation technologies may inadvertently reinforce linguistic privilege and accent-based discrimination, potentially creating new forms of digital exclusion. Overall, our study highlights the need for inclusive design and regulation by providing actionable insights for developers, policymakers, and organizations to ensure equitable and socially responsible AI speech technologies.
@inproceedings{michel2025representation, title = {“It’s not a representation of me”: Examining Accent Bias and Digital Exclusion in Synthetic AI Voice Services}, author = {Michel, Shira and Kaur, Sufi and Gillespie, Sarah Elizabeth and Gleason, Jeffrey and Wilson, Christo and Ghosh, Avijit}, booktitle = {Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency}, pages = {228--245}, year = {2025}, }


2024
2024
- ICWSM
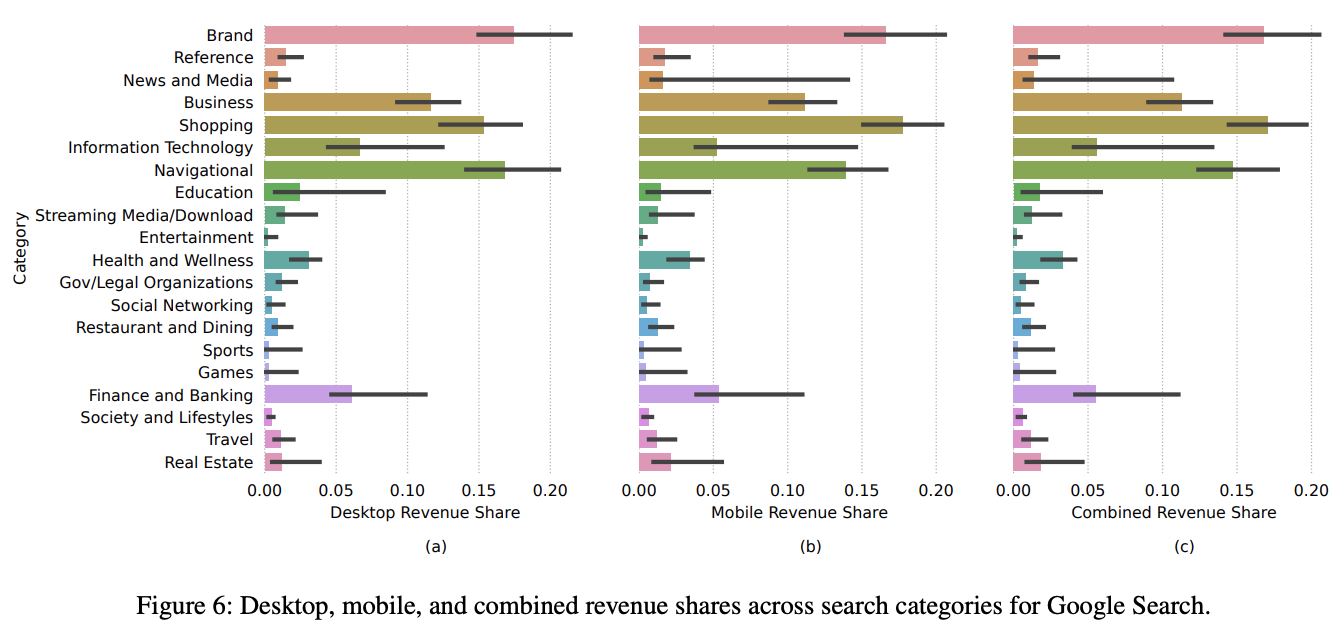 Search Engine Revenue from Navigational and Brand AdvertisingJeffrey Gleason, Alice Koeninger, Desheng Hu, and 5 more authorsIn Proceedings of the International AAAI Conference on Web and Social Media , 2024
Search Engine Revenue from Navigational and Brand AdvertisingJeffrey Gleason, Alice Koeninger, Desheng Hu, and 5 more authorsIn Proceedings of the International AAAI Conference on Web and Social Media , 2024Keyword advertising on general web search engines is a multi-billion dollar business. Keyword advertising turns contentious, however, when businesses target ads against their competitors’ brand names—a practice known as “competitive poaching.” To stave off poaching, companies defensively bid on ads for their own brand names. Google, in particular, has faced lawsuits and regulatory scrutiny since it altered its policies in 2004 to allow poaching.
In this study, we investigate the sources of advertising revenue earned by Google, Bing, and DuckDuckGo by examining ad impressions, clicks, and revenue on navigational and brand searches. Using logs of searches performed by a representative panel of US residents, we estimate that ads on these searches account for 28–36% of Google’s search revenue, while Bing earns even more. We also find that the effectiveness of these ads for advertisers varies. We conclude by discussing the implications of our findings for advertisers and regulators.
@inproceedings{gleason2024ads, title = {Search Engine Revenue from Navigational and Brand Advertising}, author = {Gleason, Jeffrey and Koeninger, Alice and Hu, Desheng and Teurn, Jessica and Bart, Yakov and Knight, Samsun and Robertson, Ronald E. and Wilson, Christo}, booktitle = {Proceedings of the International AAAI Conference on Web and Social Media}, year = {2024}, } - ICWSM
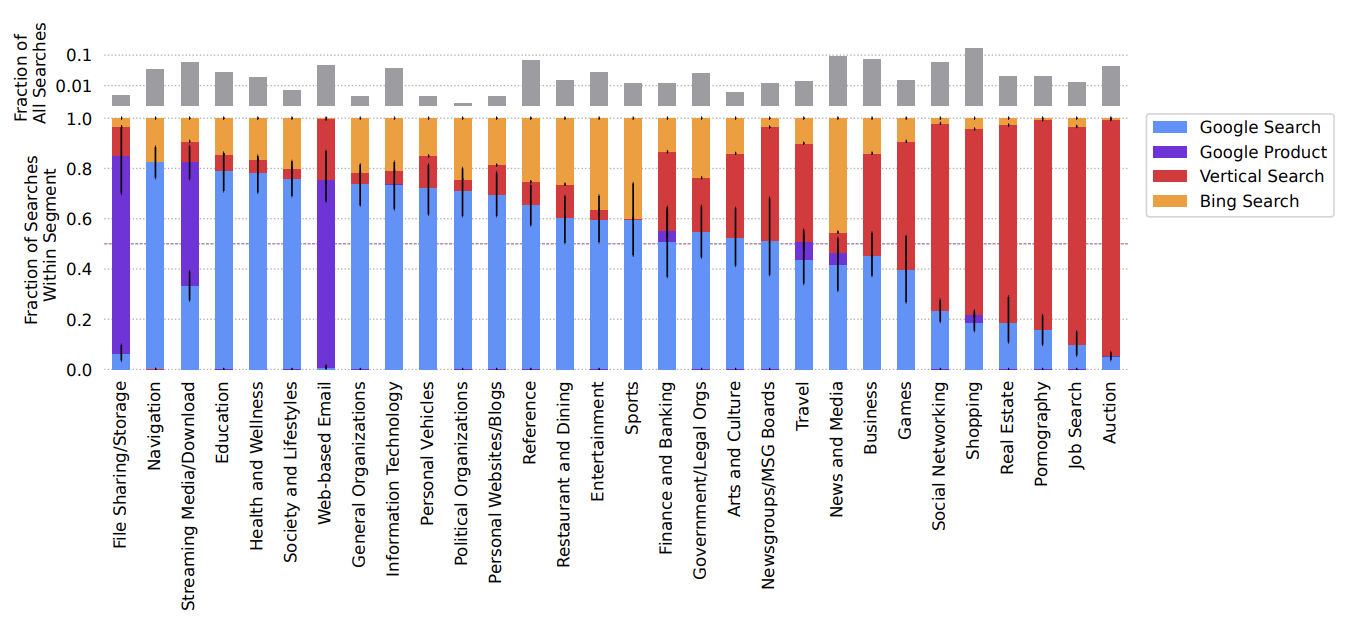 Market or Markets? Investigating Google Search’s Market Shares Under Vertical SegmentationDesheng Hu*, Jeffrey Gleason*, Muhammad Abu Bakar Aziz*, and 4 more authorsIn Proceedings of the International AAAI Conference on Web and Social Media , 2024Best Paper Honorable Mention Award
Market or Markets? Investigating Google Search’s Market Shares Under Vertical SegmentationDesheng Hu*, Jeffrey Gleason*, Muhammad Abu Bakar Aziz*, and 4 more authorsIn Proceedings of the International AAAI Conference on Web and Social Media , 2024Best Paper Honorable Mention AwardIs Google Search a monopoly with gatekeeping power? Regulators from the US, UK, and Europe have argued that it is based on the assumption that Google Search dominates the market for horizontal (a.k.a.“general") web search. Google disputes this, claiming that competition extends to all vertical (a.k.a. “specialized") search engines, and that under this market definition it does not have monopoly power.
In this study we present the first analysis of Google Search’s market share under vertical segmentation of online search. We leverage observational trace data collected from a panel of US residents that includes their web browsing history and copies of the Google Search Engine Result Pages they were shown. We observe that participants’ search sessions begin at Google greater than 50% of the time in 24 out of 30 vertical market segments (which comprise almost all of our participants’ searches). Our results inform the consequential and ongoing debates about the market power of Google Search and the conceptualization of online markets in general.
@inproceedings{hu2024monopoly, title = {Market or Markets? Investigating Google Search’s Market Shares Under Vertical Segmentation}, author = {Hu*, Desheng and Gleason*, Jeffrey and Aziz*, Muhammad Abu Bakar and Koeninger, Alice and Guggenberger, Nikolas and Robertson, Ronald E. and Wilson, Christo}, booktitle = {Proceedings of the International AAAI Conference on Web and Social Media}, year = {2024}, note = {<b>Best Paper Honorable Mention Award</b>}, } - WWW
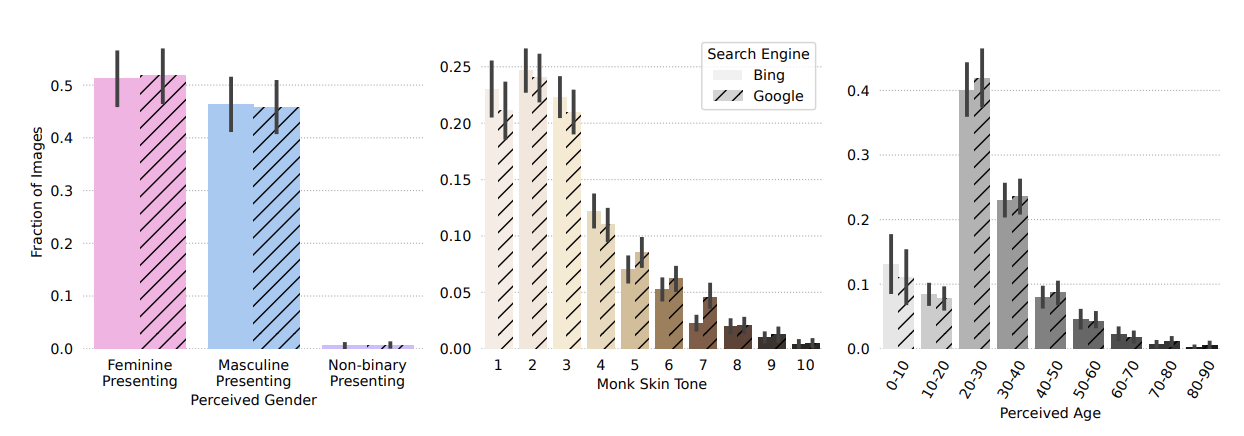 Perceptions in Pixels: Analyzing Perceived Gender and Skin Tone in Real-world Image Search ResultsJeffrey Gleason, Avijit Ghosh, Ronald E. Robertson, and 1 more authorIn Proceedings of the ACM Web Conference 2024 , 2024
Perceptions in Pixels: Analyzing Perceived Gender and Skin Tone in Real-world Image Search ResultsJeffrey Gleason, Avijit Ghosh, Ronald E. Robertson, and 1 more authorIn Proceedings of the ACM Web Conference 2024 , 2024The results returned by image search engines have the power to shape peoples’ perceptions about social groups. Existing work on image search engines leverages hand-selected queries for occupations like “doctor” and “engineer” to quantify racial and gender bias in search results. We complement this work by analyzing peoples’ real-world image search queries and measuring the distributions of perceived gender, skin tone, and age in their results. We collect 54,070 unique image search queries and analyze 1,481 open-ended people queries (i.e., not queries for named entities) from a representative sample of 643 US residents. For each query, we analyze the top 15 results returned on both Google and Bing Images.
Analysis of real-world image search queries produces multiple insights. First, less than 5% of unique queries are open-ended people queries. Second, fashion queries are, by far, the most common category of open-ended people queries, accounting for over 30% of the total. Third, the modal skin tone on the Monk Skin Tone scale is two out of ten (the second lightest) for images from both search engines. Finally, we observe a bias against older people: eleven of our top fifteen query categories have a median age that is lower than the median age in the US.
@inproceedings{gleason2024images, title = {Perceptions in Pixels: Analyzing Perceived Gender and Skin Tone in Real-world Image Search Results}, author = {Gleason, Jeffrey and Ghosh, Avijit and Robertson, Ronald E. and Wilson, Christo}, booktitle = {Proceedings of the ACM Web Conference 2024}, year = {2024}, } - ICWSM Workshop
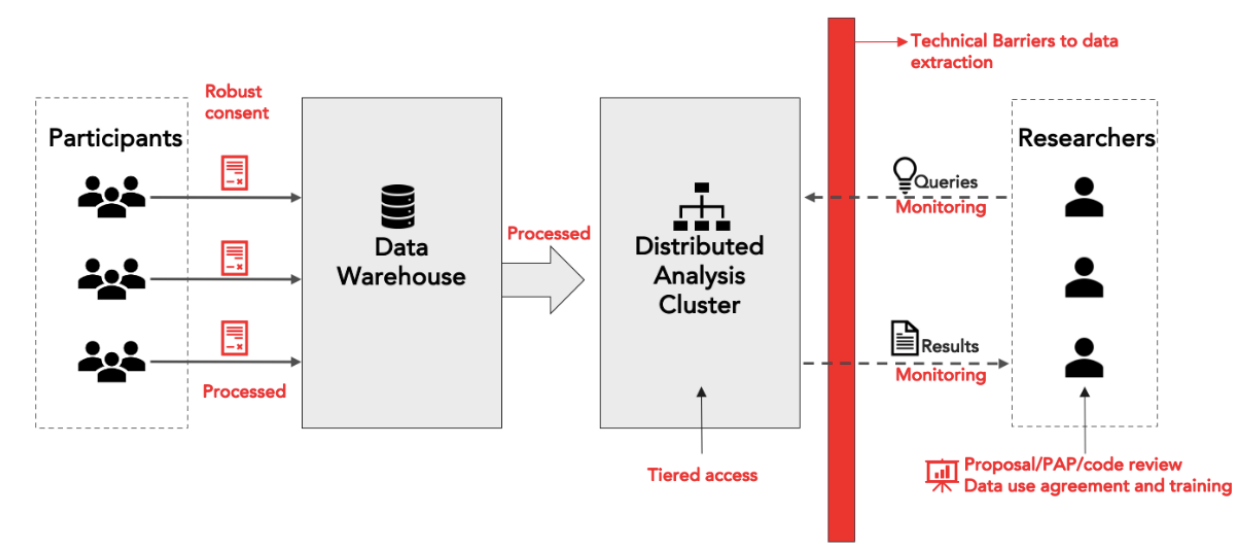 Introduction to National Internet ObservatoryAlvaro Feal, Jeffrey Gleason, Pranav Goel, and 7 more authorsData Challenge Workshop at the International AAAI Conference on Web and Social Media, 2024
Introduction to National Internet ObservatoryAlvaro Feal, Jeffrey Gleason, Pranav Goel, and 7 more authorsData Challenge Workshop at the International AAAI Conference on Web and Social Media, 2024The National Internet Observatory (NIO) aims to help researchers study online behavior. Participants install a browser extension and/or mobile apps to donate their online activity data along with comprehensive survey responses. The infrastructure will offer approved researchers access to a suite of structured, parsed content data for selected domains to enable analyses and understanding of Internet use in the US. This is all conducted within a robust research ethics framework, emphasizing ongoing informed consent and multiple layers, technical and legal, of interventions to protect the values at stake in data collection, data access, and research. This paper provides a brief overview of the NIO infrastructure, the data collected, the participants, and the researcher intake process.
@article{feal2024introduction, title = {Introduction to National Internet Observatory}, author = {Feal, Alvaro and Gleason, Jeffrey and Goel, Pranav and Radford, Jason and Yang, Kai-Cheng and Basl, John and Meyer, Michelle and Choffnes, David and Wilson, Christo and Lazer, David}, journal = {Data Challenge Workshop at the International AAAI Conference on Web and Social Media}, year = {2024}, }




2023
2023
- ICWSM
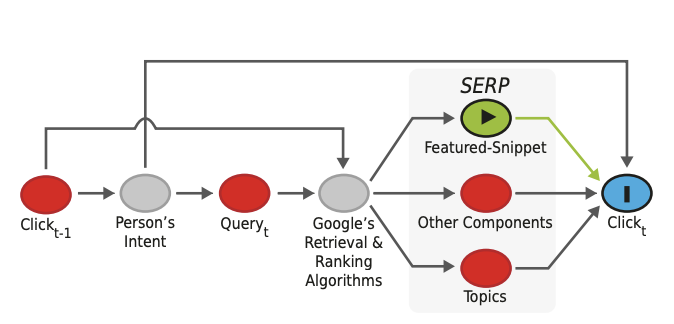 Google the Gatekeeper: How Search Components Affect Clicks and AttentionJeffrey Gleason, Desheng Hu, Ronald E. Robertson, and 1 more authorIn Proceedings of the International AAAI Conference on Web and Social Media , 2023Best Paper Award
Google the Gatekeeper: How Search Components Affect Clicks and AttentionJeffrey Gleason, Desheng Hu, Ronald E. Robertson, and 1 more authorIn Proceedings of the International AAAI Conference on Web and Social Media , 2023Best Paper AwardThe contemporary Google Search Engine Results Page (SERP) supplements classic blue hyperlinks with complex components. These components produce tensions between searchers, 3rd-party websites, and Google itself over clicks and attention. In this study, we examine 12 SERP components from two categories: (1) extracted results (e.g.
featured-snippets) and (2) Google Services (e.g.shopping-ads) to determine their effect on peoples’ behavior. We measure behavior with two variables: (1) clickthrough rate (CTR) to Google’s own domains versus 3rd-party domains and (2) time spent on the SERP. We apply causal inference methods to an ecologically valid trace dataset comprising 477,485 SERPs from 1,756 participants. We find that multiple components substantially increase CTR to Google domains, while others decrease CTR and increase time on the SERP. These findings may inform efforts to regulate the design of powerful intermediary platforms like Google.@inproceedings{gleason2023gatekeeper, title = {Google the Gatekeeper: How Search Components Affect Clicks and Attention}, author = {Gleason, Jeffrey and Hu, Desheng and Robertson, Ronald E. and Wilson, Christo}, booktitle = {Proceedings of the International AAAI Conference on Web and Social Media}, year = {2023}, note = {<b>Best Paper Award</b>}, }

2021
2021
- SPIEUseable machine learning for Sentinel-2 multispectral satellite imageryScott Langevin, Chris Bethune, Philippe Horne, and 6 more authorsIn Image and Signal Processing for Remote Sensing XXVII , 2021
One of the challenges when building Machine Learning (ML) models using satellite imagery is building sufficiently labeled data sets for training. In the past, this problem has been addressed by adapting computer vision approaches to GIS data with significant recent contributions to the field. But when trying to adapt these models to Sentinel-2 multi-spectral satellite imagery these approaches fall short. Previously, researchers used transfer learning methods trained on ImageNet and constrained the 13 channels to 3 RGB ones using existing training sets, but this severely limits the available data that can be used for complex image classification, object detection, and image segmentation tasks. To address this deficit, we present Distil, and demonstrate a specific method using our system for training models with all available Sentinel-2 channels. There currently is no publicly available rich labeled training data resource such as ImageNet for Sentinel-2 satellite imagery that covers the entire globe. Our approach using the Distil system was: a) pre-training models using unlabeled data sets and b) adapting to specific downstream tasks using a small number of annotations solicited from a user. We discuss the Distil system, an application of the system in the remote sensing domain, and a case study identifying likely locust breeding grounds in Africa from unlabeled 13-channel satellite imagery.
@inproceedings{langevin2021useable, title = {Useable machine learning for Sentinel-2 multispectral satellite imagery}, author = {Langevin, Scott and Bethune, Chris and Horne, Philippe and Kramer, Steve and Gleason, Jeffrey and Johnson, Ben and Barnett, Ezekiel and Husain, Fahd and Bradley, Adam}, booktitle = {Image and Signal Processing for Remote Sensing XXVII}, volume = {11862}, pages = {97--114}, year = {2021}, organization = {SPIE}, }
2020
2020
- KDD MiLeTSForecasting Hierarchical Time Series with a Regularized Embedding SpaceJeffrey L GleasonIn MileTS ’20: 6th KDD Workshop on Mining and Learning from Time Series , 2020
Collections of time series with hierarchical and/or grouped structure are pervasive in real-world forecasting applications. Furthermore, one is often required to forecast across multiple levels of the hierarchy simultaneously, and to have all forecasts reconcile. This paper proposes a new approach to reconciliation, whereby a regularization term penalizes deviation from the known structure of the collection in a learned embedding space. Experiments on real-world Australian travel data demonstrate that the proposed regularization outperforms state-of-the-art MinT reconciliation [24] in three different forecasting settings. These settings include two challenging forecasting settings: short training sequences and a long forecast horizon. We also show that our proposed regularization term is robust to the relative size of the learned embedding space.
@inproceedings{gleason2020forecasting, title = {Forecasting Hierarchical Time Series with a Regularized Embedding Space}, author = {Gleason, Jeffrey L}, booktitle = {MileTS ’20: 6th KDD Workshop on Mining and Learning from Time Series}, year = {2020}, }
2019
2019
- ICML AISGUsing deep networks and transfer learning to address disinformationNuma Dhamani, Paul Azunre, Jeffrey L Gleason, and 4 more authorsIn ICML AI for Social Good Workshop , 2019
We apply an ensemble pipeline composed of a character-level convolutional neural network (CNN) and a long short-term memory (LSTM) as a general tool for addressing a range of disinformation problems. We also demonstrate the ability to use this architecture to transfer knowledge from labeled data in one domain to related (supervised and unsupervised) tasks. Character-level neural networks and transfer learning are particularly valuable tools in the disinformation space because of the messy nature of social media, lack of labeled data, and the multi-channel tactics of influence campaigns. We demonstrate their effectiveness in several tasks relevant for detecting disinformation: spam emails, review bombing, political sentiment, and conversation clustering.
@inproceedings{dhamani2019using, title = {Using deep networks and transfer learning to address disinformation}, author = {Dhamani, Numa and Azunre, Paul and Gleason, Jeffrey L and Corcoran, Craig and Honke, Garrett and Kramer, Steve and Morgan, Jonathon}, booktitle = {ICML AI for Social Good Workshop}, year = {2019}, } - TTODisinformation: Detect to Disrupt.Craig Corcoran, Renee DiResta, David Morar, and 6 more authorsIn Truth and Trust Online Conference , 2019
@inproceedings{corcoran2019disinformation, title = {Disinformation: Detect to Disrupt.}, author = {Corcoran, Craig and DiResta, Renee and Morar, David and Dhamani, Numa and Sullivan, David and Gleason, Jeffrey L and Azunre, Paul and Kramer, Steve and Ruppel, Becky}, booktitle = {Truth and Trust Online Conference}, year = {2019}, }